YouTube Kanal von Martin Wabnik
Dieser YouTube Kanal bietet über 400 hochwertige Mathematik-Videos zu verschiedenen Themen der Schulmatheamtik. Dabei geht es um ein tiefes Verständnis der Mathematik (deep learning) und nicht um die Bereitstellung sinnentleerter Lösungsrezepte. Hinter jedem Video steckt ein didaktisches Konzept, welches entschieden sprachlich und visuell umgesetzt wird. Jeder Mensch, der Mathematik wirklich verstehen möchte, wird hier das finden, wonach er lange gesucht hat.
https://www.youtube.com/@martinwabnik/playlists
Links zu einzelnen Videos
Hauptsatz der Differential – und Integralrechnung – anschauliche Erklärung
Exponentialfunktion mit Salzteig
Ortsvektor – Definition
pq-Formel für quadratische Gleichungen
Kehrwertregel – anschauliche Erklärung
Kugeloberfläche – Kosmetik und Nanopartikel
Mathe einfach unterrichten – die relative Häufigkeit und ein folgenreicher Irrtum
Das empirische Gesetz der großen Zahlen gibt es in vielen Formulierungen, wobei manche falscher als andere sind. Völlig falsch ist die folgende Formulierung, die man auf den Seiten des Vereins MUED e. V. finden kann (wenn man Mitglied ist):
„Dieses berühmte Gesetz der Großen Zahl besagt, dass bei vielen unabhängigen Wiederholungen eines Zufallsexperiments, sei es Münzwurf, Würfeln, Lotto, Kartenspielen oder was auch immer, die relative Häufigkeit und die Wahrscheinlichkeit eines Ereignisses immer näher zusammenrücken müssen: Je häufiger wir eine faire Münze werfen, desto näher kommt der Anteil von ‚Kopf‘ seiner Wahrscheinlichkeit ein halb, je häufiger wir würfeln, desto näher kommt der Anteil der Sechsen der Wahrscheinlichkeit für Sechs, und je häufiger wir Lotto spielen, desto näher kommt die relative Häufigkeit der 13 der Wahrscheinlichkeit der 13. An diesem Gesetz gibt es nichts herumzudeuteln, dieses Gesetz ist in gewisser Weise die Krönung der gesamten Wahrscheinlichkeitstheorie.“
Es wird behauptet, Jakob Bernoulli (1654 – 1705) habe das empirische Gesetz der großen Zahlen als erster formuliert. Das ist aber nicht richtig – zumindest dann, wenn man die gängigen Formulierungen berücksichtigt. Bernoulli schrieb z. B. nicht, die relativen Häufigkeiten eines Ereignisses A pendelten sich bei hinreichend großer Anzahl n der Versuchswiederholungen bei der Wahrscheinlichkeit von A ein. Ebensowenig schrieb er, die relativen Häufigkeiten eines Ereignisses A stabilisierten sich mit zunehmender Anzahl der Versuchsdurchführungen bei der Wahrscheinlichkeit von A und er schrieb auch nicht, die relativen Häufigkeiten von A müssten sich mit zunehmender Anzahl der Versuchsdurchführungen der Wahrscheinlichkeit von A annähern.
Und hier ist – in der deutschen Übersetzung – das, was Bernoulli tatsächlich schrieb:
„Satz: Es möge sich die Zahl der günstigen Fälle zu der Zahl der ungünstigen Fälle genau oder näherungsweise wie , also zu der Zahl aller Fälle wie \( \frac{r}{r+s}=\frac{r}{t} \) – wenn \( r+s=t \) gesetzt wird – verhalten, welches letztere Verhältniss zwischen den Grenzen \( \frac{r+l}{t} \) und \( \frac{r-l}{t} \) enthalten ist. Nun können, wie zu beweisen ist, soviele Beobachtungen gemacht werden, dass es beliebig oft (z. B. c-mal) wahrscheinlicher wird, dass das Verhältniss der günstigen zu allen angestellten Beobachtungen innerhalb dieser Grenzen liegt als ausserhalb derselben, also weder grösser als \( \frac{r+l}{t} \) , noch kleiner als \( \frac{r-l}{t} \) ist.“ (Bernoulli 1713, S. 104), in der Ausgabe: Wahrscheinlichkeitsrechnung (Ars conjectandi), Dritter und vierter Theil, übersetzt von R. Haussner, Leipzig, Verlag von Wilhom Engelmann, 1899)
Das, was Bernoulli schrieb, ist übrigens richtig und kommt dem schwachen Gesetz der großen Zahlen sehr nahe.
Es sind beliebig viele Situationen denkbar, in denen die relative Häufigkeit eines Ereignisses sich nicht der Wahrscheinlichkeit dieses Ereignisses nähert, sondern sich von diesem entfernt.
Ein Beispiel: Angenommen, wir werfen zufällig eine Münze, sodass wir die Ergebnisse Z (Zahl) und K (Kopf) erhalten können. Dabei sollen beide Ergebnisse jeweils die Wahrscheinlichkeit 0,5 haben. Nehmen wir weiter an, wir hätten die Münze 100-mal geworfen und 50-mal Z sowie 50-mal K erhalten. Dann ist die relative Häufigkeit von Z gleich 0,5. Wenn wir nun die Münze nochmals werfen, erhalten wir entweder Z – dann ist die relative Häufigkeit von Z gleich \(0,\overline{5049}\) – oder wir erhalten K – dann ist die relative Häufigkeit von Z gleich \(0,\overline{4851}\). In beiden Fällen entfernt sich die relative Häufigkeit Z wieder von der Wahrscheinlichkeit von Z. Wir können, nachdem wir beim Versuch Nummer 101 das Ergebnis Z erhalten haben, bei nachfolgenden Versuchsdurchführungen immer wieder Z erhalten. Die relativen Häufigkeiten für Z sind dann:
\(\approx 0,5098\), \(\approx 0,5146\), \(\approx 0,5192\), \(\approx 0,5283\), usw.
Damit rückt also die relative Häufigkeit von Z immer weiter von der Wahrscheinlichkeit von Z ab, was dem angeblichen Gesetz der großen Zahlen widerspricht.
Das empirische Gesetz der großen Zahlen wird oft damit begründet, dass zwar auch ungewöhnliche Ergebnisse vorkommen können, die seien aber so unwahrscheinlich, dass sie praktisch nie vorkommen. Z. B. sei beim 30-fachen Münzwurf das Ergebnis KKKKKKKKKKKKKKKKKKKKKKKKKKKKKK sehr ungewöhnlich und auch unwahrscheinlich, während das Ergebnis KZZKZKKKZKZZKZZZKKKZKZKKKZZZZK viel normaler und deshalb wahrscheinlicher sei.
Das ist nicht nur deshalb falsch, weil beide Ergebnisse genau die gleiche Wahrscheinlichkeit haben, sondern auch deshalb, weil wir Menschen das, was an bestimmten Ergebnissen ungewöhnlich sein soll, in die Ergebnisse hineinfantasieren. Anders gesagt: Die Münze „weiß“ nichts von ungewöhnlichen Ergebnissen. Schauen wir uns dazu ein Beispiel an:

Angenommen, wir haben 10 Kugeln mit den Ziffern von 0 bis 9. Die Kugel mit der 0 ist grün, alle anderen sind gelb. Wir ziehen zufällig zehnmal mit Zurücklegen und mit Reihenfolge.
Achteten wir nur auf die Farben, empfänden wir das Ergebnis

vermutlich nicht als ungewöhnlichn. Käme dann aber bei der Betrach-tung der Zahlen das hier zum Vorschein

gälte die Stichprobe aber wohl doch als ungewöhnlich.
Wenn wir wollen, können wir aber noch ganz andere Maßstäbe ansetzen: Eine Stichprobe soll als ungewöhnlich gelten, wenn die Ziffernfolge in den ersten Nachkommastellen von π vorkommt. Die Stichprobe
ist gewöhnlich, weil sie nicht einmal unter den ersten 200 Millionen Nachkommastellen von π vorkommt. Die Stichprobe

ist ungewöhnlich, weil sie an Position 3 794 572 vorkommt. Die Stichprobe

kommt sogar an Position 851 vor und ist damit quasi extrem ungewöhnlich.
Egal ob ungewöhnlich oder nicht: Die Wahrscheinlichkeit jeder Stichprobe ist exakt die gleiche, nämlich: \[\frac{1}{10\,000\,000\,000}\]
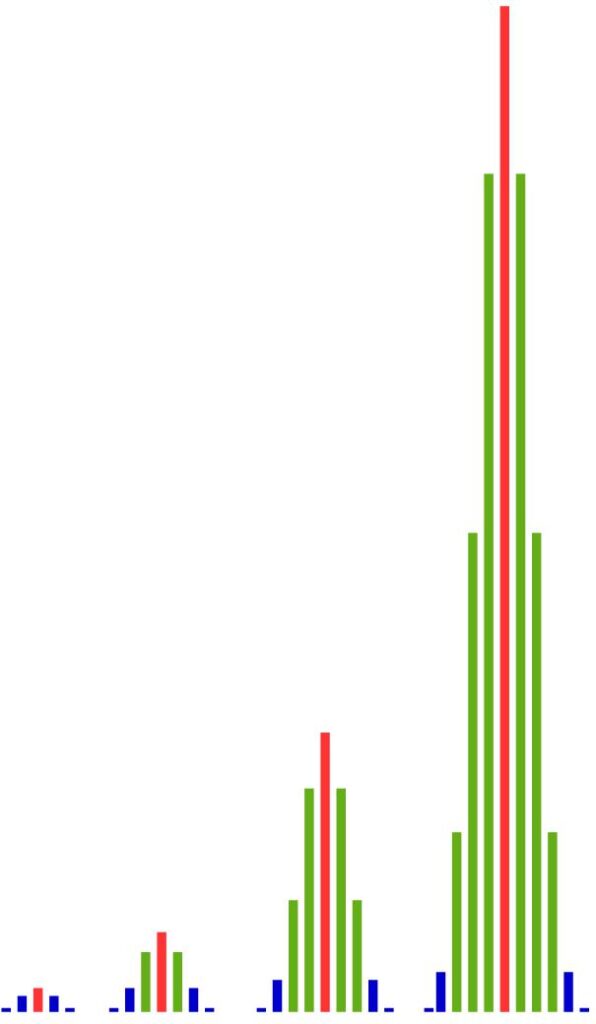
Schauen wir uns ein Beispiel dazu an: Wir ziehen zufällig eine Kugel aus einem Behälter, in dem sich zwei Kugeln befinden. Eine Kugel ist blau, die andere ist rot. Wir ziehen mehrmals mit Zurücklegen und mit Reihenfolge.

Wir wollen uns im Weiteren für die Anzahlen der roten Kugeln interessieren. In den folgenden Tabellen sind diese Anzahlen in Abhängigkeit von den Versuchsdurchführungen aufgelistet. Beim 8-maligen Ziehen gibt es z. B. 56 Ergebnisse mit 3 roten Kugeln.
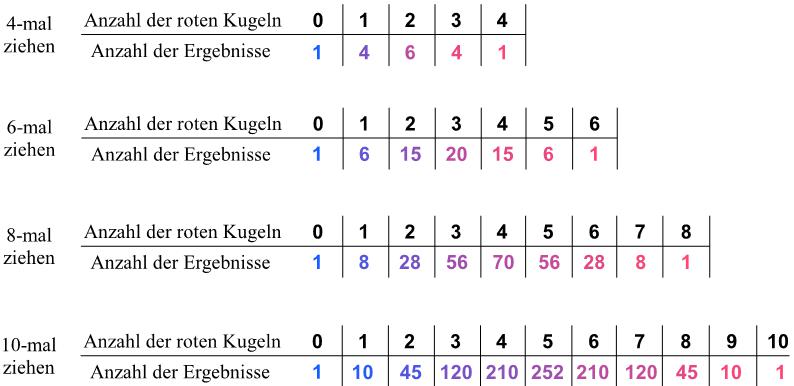
Diese Anzahlen werden von den Säulendiagrammen links maßstabsgetreu dargestellt. Wie wir sehen, wachsen mit zunehmender Anzahl der Versuchsdurchführungen die Anzahlen der Ergebnisse in der Mitte viel schneller als am Rand. Je öfter wir den Versuch durchführen, desto größer werden die Unterschiede zwischen der Mitte und dem Rand.
Das heißt: Es gibt einfach viel mehr Ergebnisse mit ungefähr 50 % roten Kugeln als es Ergebnisse mit viel weniger oder viel mehr roten Kugeln gibt. Und der Anteil der Ergebnisse in der Nähe der Mitte wird immer größer, je größer die Anzahl der Versuchsdurchführungen ist.
Dieses Phänomen können wir auch mit anderen Anteilen roter Kugeln in der Grundgesamtheit beobachten: Sind in der Grundgesamtheit zwei Drittel der Kugeln rot, sehen wir eine Häufung der Ergebnisse mit zwei Dritteln roter Kugeln.
Was wir hier sehen, können wir zwar etwas vereinfachend – aber nicht falsch – mit folgendem Satz zusammenfassen: Die relativen Häufigkeiten roter Kugeln sind in den meisten Ergebnissen so ähnlich wie die Wahrscheinlichkeit, eine rote Kugel zu ziehen.
Mit den Begriffen der Statistik hört sich das so an: Die meisten Stichproben sind so ähnlich wie die Grundgesamtheit.
Wenn wir also eine Münze 100-mal werfen und wir ca. 50-mal K erhalten, liegt das nicht daran, dass sich die relative Häufigkeit stabilisiert oder die Münze auf einen Ausgleich zwischen K und Z bedacht ist oder daran, dass eine dunkle Macht den Fall der Münze beeinflusst, sondern schlicht und ergreifen daran, dass es viel, viel mehr Ergebnisse gibt, die ca. 50-mal K enthalten als es Ergebnisse gibt, die viel weniger oder viel mehr K enthalten.